2.2 Formate für bewegte lineare Daten
2.2.1 Videokompression mit MPEG (Moving Picture Experts Group)
Zur gemeinsamen Kodierung von Bewegtbildern und Audiodaten hat sich in vielen Bereichen das MPEG-1-Format durchgesetzt, das seit 1993 auch ein ISO International Standard ist. Die Datenrate die für MPEG-Daten angestrebt wird, liegt bei 1,2 Mbit/s und entspricht damit der Datenrate, die CD-Spieler bei einfacher Geschwindigkeit erreichen.
Visuelle Daten werden nicht in dem später für die Darstellung nötigen RGB-Farbraum, sondern im YCrCb-Farbraum dargestellt. Die Y-Komponente enthält dabei die Luminanz (Helligkeit) des Bildes, die beiden C-Komponenten die Chrominanz (Farbigkeit). Da für die Bildwahrnehmung im menschliche Auge die Luminanz eine wichtigere Rolle als die Chrominanz spielt, wird die Luminanzkomponente mit entsprechend höherer Datenrate kodiert. Man erhält dadurch eine - im Gegensatz zu einer RGB-Kodierung mit gleicher Datenrate in allen drei Kanälen - deutlich bessere subjektive Qualität.
Um die Qualität darüberhinaus zu erhöhen, ist MPEG als vorzugsweise asymmetrische Kompression konzipiert. Asymmetrisch bedeutet in diesem Zusammenhang, daß für die Kodierung ein wesentlich höherer Aufwand benötigt wird als für die Dekodierung.
Der Videostrom wird bei MPEG aus vier verschiedenen Einzelbildtypen, sogenannten Frames, zusammengesetzt. Diese Frametypen können in beinahe beliebiger Reihenfolge liegen. Die Reihenfolge wird vom Kodierer festgelegt.
I-Bilder (Intra Coded Pictures)
I-Bilder kodieren gesamte Einzelbilder, ohne sich auf andere Bilder des Datenstroms zu beziehen. Die Daten eines I-Bildes stellen also ein Einzelbild komplett dar. Die Kompressionstechnik ist stark an die verlustbehaftete JPEG-Kompression angelehnt.
P-Bilder (Predictive Coded Pictures)
Bei P-Bildern macht man sich die Tatsache zunutze, daß sich zwischen zwei Bildern einzelne Bildbereiche häufig nicht, oder nur wenig ändern, sondern nur verschieben. Um geringe Unterschiede zwischen Bildbereichen zu sichern, wird nur die Differenz der beiden Bereiche gesichert. Die für die Differenz benötigte Datenmenge ist deutlich geringer als für die komplette Neukodierung des Bereichs. Außerdem muß der Bewegungsvektor des Bereichs gesichert werden.
P-Bilder beziehen sich bei dieser Kodierung stets auf das vorhergehende P- oder I-Bild, deshalb muß das jeweils letzte P- oder I-Bild im Dekodierer gespeichert werden.
Weiterhin können Bildbereiche ebenso wie in I-Bildern komplett kodiert werden. Die Auswahl, welche Bestandteile neu und welche "vorhersehend" (predictive) kodiert werden, ist dem Kodierer überlassen.
B-Bilder (Bidirectionally Predictive Coded Pictures)
Bei B-Bildern wird zusätzlich noch das nachfolgende P- oder I-Bild in die Berechnung mit einbezogen. Dadurch lassen sich Bestandteile, die beispielsweise durch die Bewegung eines Vordergrundobjekts im vorherigen Bild noch nicht verfügbar und erst im nachfolgenden Bild sichtbar sind, effizient kodieren.
D-Bilder (DC Coded Pictures)
D-Bilder sind, wie I-Bilder, als ganzes kodiert und beziehen sich nicht auf andere Bilder. Jedoch wird hier nur der DC-Koeffizient (siehe JPEG-Kompression) der Diskreten Cosinus-Transformation gespeichert. Diese Bilder werden für die normale Wiedergabe nicht benötigt und nur bei schnellem Vor- oder Rücklauf dekodiert um wenigstens eine grobe Vorstellung des Inhalts zu vermitteln. Da heutige Dekodierer meist genügend schnell sind, um I-Bilder in hoher Geschwindigkeit darzustellen, und I-Bilder im Datenstrom meist in regelmäßigen Abständen auftreten, werden D-Bilder in der Praxis kaum verwendet.
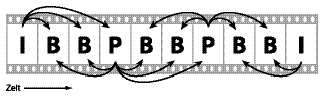
Da nur bei I-Bildern gewährleistet ist, daß das komplette Bild dekodierbar ist, müssen für einzelne P- oder B-Bilder alle Bilder seit dem letzten I-Bild mitdekodiert werden. Somit ist es nicht sinnvoll, nur ein einziges I-Bild am Anfang des Datenstroms zu plazieren und alle Folgebilder als P- oder B-Bild zu kodieren. Für einen Zugriff auf ein beliebiges Bild müßten so alle Bilder seit dem ersten I-Bild dekodiert werden, was ohne weitere Zwischenspeicherung einen viel zu hohen Rechenaufwand erfordern würde. Für praktische Anwendungen hat sich eine Kodierung in der Folge IBBPBBPBB IBBPBBPBB... als sinnvoll herausgestellt.
Abbildung 5: Typische MPEG-Framereihenfolge und mögliche Abhängigkeiten zwischen einzelnen Bildern.
|
2.2.2 Audiokompression mit MPEG Layer-3 (MP3)
Für die Kodierung des Audiostroms in MPEG-1 Daten stehen drei verschiedene Techniken mit unterschiedlichem Kodierungs- und Dekodierungsaufwand zur Verfügung. Diese sind in sogenannten
Layern
(Ebenen) definiert. Dekodierer eines höheren Layers müssen dabei immer auch Datenströme niedrigerer Ebenen dekodieren können.
Die derzeit wohl beliebteste Kodierung ist die der Ebene drei, die unter der etwas irreführenden Bezeichnung MP3
für reine Musikkodierung verwendet wird. MP3 steht dabei nicht für MPEG-3 (diesen Standard gibt es nämlich gar nicht), sondern für MPEG Layer-3.
Das MP3-Format wurde maßgeblich vom Fraunhofer Institut für Integrierte Schaltungen in Kooperation mit der Universität Erlangen entwickelt [4]. Die hohe Kompression bei gleichzeitig guter Qualität wird durch die Anwendung eines psychoakustischen Modells erreicht, das in aufwendigen Versuchen mit Testpersonen ermittelt wurde. Man macht sich dabei das Phänomen zunutze, daß Audiosignale vom menschlichen Ohr nicht wahrgenommen werden, wenn sie von anderen, meist lauteren Signalen überdeckt werden (Maskierungseffekt).
Tabelle 2: Typische MP3-Performance (Quelle: Fraunhofer IIS-A)
|
Tonqualität
|
Bandbreite
|
Modus
|
Bitrate
|
Kompression
|
|
Telefon
|
2,5 kHz
|
mono
|
8 kbps
|
96:1
|
|
besser als KW
|
4,5 kHz
|
mono
|
16 kbps
|
48:1
|
|
besser als AM
|
7,5 kHz
|
mono
|
32 kbps
|
24:1
|
|
ähnlich zu FM
|
11 kHz
|
stereo
|
56...64 kbps
|
26...24:1
|
|
nahe-CD
|
15 kHz
|
stereo
|
96 kbps
|
16:1
|
|
CD
|
>15 kHz
|
stereo
|
112...128 kbps
|
14...12:1
|
Für die Kodierung wird das Tonsignal zunächst in Blöcke zu mehreren Samples
(einzelne Abtastwerte des Signals) aufgeteilt und in 32 Frequenzbereiche aufgespalten. Die Blöcke werden mittels Diskreter Cosinus-Transformation, Quantisierung und Lauflängenkodierung komprimiert. Wichtige, hörbare Frequenzbereiche werden mit relativ hoher Datenrate kodiert. Für andere Frequenzbereiche wird der Signal-to-Mask-Ratio
ermittelt und die Datenrate im jeweiligen Frequenzbereich durch Quantisierung so weit verringert, daß das entstehende Quantisierungsrauschen (Fehler im Signal) gerade noch unter der Maskierungsschwelle liegt.
Joint Stereo
Um Stereosignale effizient kodieren zu können bietet MPEG Layer-3 als Besonderheit das Joint Stereo-Format. Man nutzt dabei aus, daß bei Stereosignalen meist nur geringe Unterschiede zwischen den beiden Tonkanälen bestehen [4]. Bei Joint Stereo wird die Differenz zwischen den beiden Kanälen ermittelt und mit etwa 30 % der verfügbaren Bandbreite kodiert. Das eigentliche Signal kann mit den verbleibenden 70 % kodiert werden. Diese Technik ermöglicht ein qualitativ insgesamt höherwertiges Signal bei gewissen Verlusten in der Kanaltrennung.
2.2.3 Echtzeit Streaming von Video- und Audiodaten via RTP und RTSP
Für die Echtzeit-Datenübertragung von audiovisuellen Daten (Streaming) gibt es zwei grundsätzliche Übertragungsmöglichkeiten: Unicast
(one-to-one) und Multicast
(one-to-many) [5].
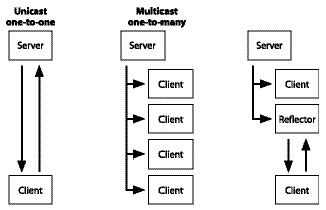
Im Unicast-Verfahren schickt der sogenannte Medienserver jeweils einen Datenstrom direkt an einen einzelnen Empfänger. Im Multicast-Verfahren wird nur ein Datenstrom in jeden Ast eines Netzwerks übertragen und kann von mehreren Endnutzern empfangen werden. Somit muß der Medienserver nicht mehrere Datenströme verschicken - die insgesamt benötigte Bandbreite wird drastisch verringert. Für dieses Verfahren muß jeder Router im Netzwerk wissen, ob sich in den angeschlossenen Teilästen Empfänger des Datenstroms befinden. Da dieses Verfahren nicht von allen Routern unterstützt wird, ist es möglich daß Empfänger die Multicast-Pakete nicht erhalten. Um dennoch den Datenstrom zu empfangen, können Reflektoren eingesetzt werden, die den Datenstrom per Multicast vor dem betreffenden Router erhalten und diesen als einzelnen Strom (im Unicast-Verfahren) an den Endempfänger schicken.
Abbildung 6: Datenstromübertragung per Unicast, Multicast und Reflektor.
|
Real Time Streaming Protocol (RTSP)
Zur Kontrolle und Steuerung des Datenstroms wird vielfach das Real Time Streaming Protocol
eingesetzt [6]. Die Syntax von RTSP ist stark an das Hypertext Transfer Protocol
(HTTP) angelehnt. Wichtige Unterschiede zu HTTP bestehen darin, daß im RTSP auch der Server Anfragen an den Client senden kann - beispielsweise um Statusinformationen wie Paketverluste abzurufen. Weiterhin wird bei RTSP der Status der Kommunikationssitzung gespeichert, so daß der Server den Client bei jeder Anfrage eindeutig identifizieren kann und die Anfrage in Kontext zu vorherigen Anfragen stellen kann.
Operationen, die vom RTSP unterstützt werden, sind das Abrufen von Streams vom Server, die ,Einladung" eines Servers zu einer bestehenden Konferenz (entweder zur Wiedergabe oder zur Aufnahme eines Stroms), das Ankündigen von zusätzlichen verfügbaren und verfügbar werdenden Daten (beispielsweise ein Tonkanal in anderer Sprache), sowie der generelle Informationsaustausch zwischen Client und Server.
Das RTSP überträgt die Audio- und Video-Daten jedoch nicht selbst - dies muß mittels eines anderen Protokolls, beispielsweise dem Real Time Transport Protocol
(RTP) geschehen.
Real Time Transport Protocol (RTP)
Das Real Time Transport Protocol spezifiziert die Übertragung von Medienstreams über Netzwerke [7]. Das verwendete Datenformat ist dabei nicht festgelegt und wird mittels sogenanntem Payload Type Identifier
angekündigt. Damit kann das RTP auch für proprietäre Datenformate (QuickTime, RealVideo) verwendet werden. Die RTP-Pakete werden sequentiell numeriert, so daß sie beim Empfänger gegebenfalls in die korrekte Reihenfolge sortiert werden können.
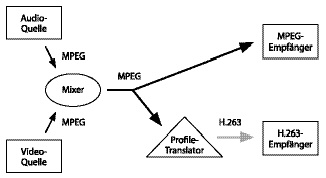
Das RTP erzielt durch den Einsatz von Mixern
und Translatoren
eine hohe Flexibilität, was Datenquellen und -formate betrifft. Mixer können einzelne Datenströme aus unterschiedlichen Quellen kombinieren und als gemeinsamen Strom weiterversenden. Somit können Audio- und Videodaten von unterschiedlichen Servern stammen, die selbst nichts voneinander wissen. Translatoren können das Datenformat oder das Übertragungsprotokoll in ein anderes übersetzen. So könnte ein eingehender MPEG-Datenstrom in ein anderes Format übersetzt werden, so daß ein Empfänger, der MPEG nicht dekodieren kann, die Daten dennoch interpretieren kann.
Abbildung 7: Manipulation von RTP-Datenströmen durch Mixer und Translatoren.
|
Vorherige Seite | Inhalt | Nächste Seite