UnicodeChecker 1.12¶
570 words on earthlingsoft
 UnicodeChecker 1.12 was released today. And Steffen came up with a bunch of improvements for this release.
UnicodeChecker 1.12 was released today. And Steffen came up with a bunch of improvements for this release.
Diff Utility
If you are dealing with text, you may from time to time end up in situations where you wonder why some string isn’t processed correctly. Or why one string is processed correctly and another one which should be similar isn’t. Often such problems are caused by some unintended Unicode character ending up in the text – say a non-breaking space instead of a simple one – or because different normalisation forms are used. Both cases give you strings that usually look the same on screen but which aren’t exactly identical and thus may lead to problems when being processed or compared (without due care).
So far, UnicodeChecker offered the Split Up tool to get down and dirty with your Unicode strings. This version introduces the new Diff tool which not just splits up strings to their Unicode building blocks but also offers to compare two such strings, complete with a visualisation of the differences. That should make it fairly easy to pinpoint the problem you are dealing with. Uh and be sure to type in a long string and enjoy the horizontal scrolling.

Improved Normalisation Utility
With the Diff Utility being in place, the Normalisation Utility has become a bit more verbose and helpful when dealing with Normalisation issues. Where previous versions just displayed an exclamation mark to indicate that the string you entered was changed by normalisation, the updated version offers a slightly more verbose button instead.
This user interface may not be perfect, but it was the best we could come up with so far while keeping things in limited space and without the window looking too nervous while you are typing. The main benefit of having that extra button is that whenever you are dealing with normalisations, you are just a single click away from having the string and its normalised version displayed in the Diff Utility with the differences being highlighted.

Improved Finding
The codepoint find sheet has been improved to let you exclude terms from your matches by prefixing them with a minus sign. Because there are so many codepoints it happens from time to time that you are searching for a term that is contained in a common part of codepoint names. In that situation being able to exclude the unwanted term can speed things up.
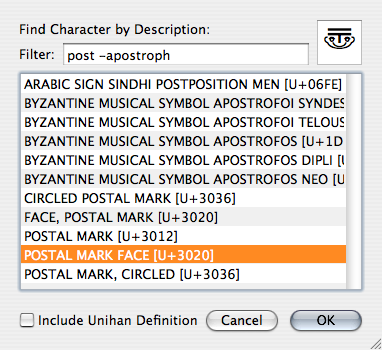
Say, you are trying to look for the funny Japanese post symbol 〠. In the past you entered ‘post’ into the find field and got and had to manually track down the symbol you wanted among all the apostrophes while cursing. Now you’ll just enter ‘post -apostroph’ instead:
Furthermore
To top things off, this release also includes a number of further improvements. Ranging from the inclusion for Sparkle to check for updates, to the inclusion of information from the HangulSyllableType file in the Misc tab to better toolbar handling and accessibility of the Utilities window, to small UI improvements, all the way to solving some odd problems that users saw when using the application on X.3.
Bonus question for Cocoa programmers: What happens when you save a string consisting of the U+0 character to a property list and then try to read that? How does the result depend on the version of Mac OS X you are running? Bonus points for pointing to the documentation explaining that behaviour.
