Prestissimo¶
1058 words
In our departmental library we have an odd catalogue system. It’s called Allegro. It has been around for some decades. And you can tell. The bottom line is that everybody hates it and that it does a fairly good job when it comes to preventing people from finding the books they are interested in.
I have been told that there are better systems around but for a number of reasons including one but quite possibly many of money, politics, laziness, incompetence we remain stuck with this sucky one. Which means that everybody who has to actually use it hates it.
Our library’s advantage is that it’s rather small and cleverly / idiosyncratically ordered with all monographs being in the shelves by the name of their authors. If you need one of those you don’t even need a catalogue. But when it comes to lecture notes, conference volumes or special series it’s certainly helpful to have the catalogue at hand - particularly as some of the more obscure stuff has been moved to separate basement rooms for space reasons.

The bottom line is that everybody hates the system. For the simple reason that the software is a pain to use. Even though it is said that backwards compatibility is the only thing the people at Microsoft are good at, the wonderful Allegro software we have does not run on current Windows versions. And apparently it took our computer people quite a few attempts to find a DOS emulation for Linux which does the trick.
As a consequence using the catalogue means that you have to start a process in a super slow DOS window (the speed of which - as a colleague recently pointed out - you can increase from 6MHz in 0.5MHz steps by pressing Control-Shift-F12. I’m not kidding!) And in that window you can only search by author name. Well, the ‘catalogue’ really starts up as a long list of author names and nothing else.
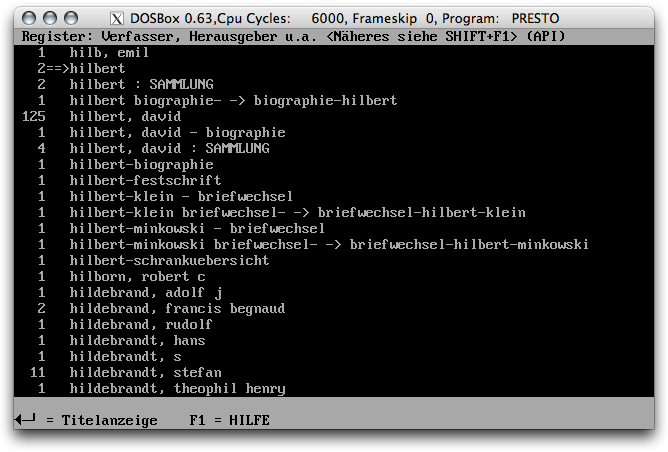
Then you ask someone clever and they’ll tell you that pressing Option Alternate-2, Alternate-3 and so on will give you lists of book titles, publishers &c. Apparently they forgot to clearly indicate that in the user interface. Ah well, MS-DOS mindset and all. Once you know it that’s great. Unless you’re opening the application from your Mac whose X11 seems to somehow ‘swallow’ the option key in its standard setup and thus renders the ‘feature’ useless. I am sure that setting can be changed, but usually I want a book rather than
It somehow came out that the ‘database’ that software uses is more of simple text file. At a closer look said text file turned out to have a line per book, fields separated by a zero byte and beginning with a number which indicates the meaning of the field. I figured it’d probably be more efficient to just do a text find in that file than using the actual catalogue application would be. And it’d only be marginally more effort to dumbly parse the data into an application and display them in a table view.
Which I did. And low-brow Cocoa was the lazy-man’s tool for this, letting me do the relevant things in less than two hours. Actually less than one hour if you count the actual work. But working with Bindings means that you easily have an application that can crash before you wrote any code and being me means that you’ll have to kick the UI at least long enough to make it semi-sucky.
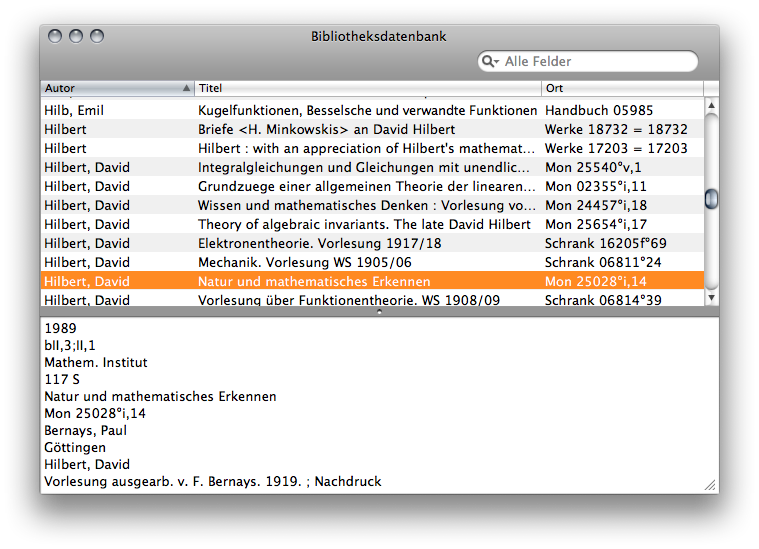
In fact the most tricky part was reading the text file. Cocoa only knows about reasonably current text encodings. In particular it doesn’t know about ancient MS-DOS encodings. Luckily I already knew that Core Foundation can do just that. In case you need to read such ancient files as well and need to program that (rather than using a reasonably competent text editor, say), the following lines of code may just do the trick:
NSData * data = [NSData dataWithContentsOfFile:dataPath]; NSString * s = (NSString*) CFStringCreateWithBytes(NULL, [data bytes], [data length], kCFStringEncodingDOSLatin1, false);
… where dataPath points to the text file in question and kCFStringEncodingDOSLatin1 should be replaced with the appropriate encoding out of the more than 100 encodings Core Foundation knows about (it even knows about EBCDIC which doesn’t just look like a typo but is also said to be as close to encryption as you can get with unencrypted text).
Of course this doesn’t answer all questions and I couldn’t do everything one might consider ‘nice’ with this little effort. E.g. I could really do with a one-line-of-code way for downloading stuff from SFTP that graciously handles the keychain interaction and it’s still not clear to me which minimal steps will make the application automatically save the last used sort order to its preferences and re-use them when running the next time.
Finally, I wouldn’t mind would appreciate if Cocoa-minded people could throw in their two cents on the following issues as well. First: Garbage Collection The application’s memory usage is too high (50MB for a 6MB text file which after possibly storing it as UTF-16 and some duplication I do should give me around 20MB of data). My suspicion is that something dodgy is going on there with the garbage collection but my naïve attempt at running Instruments didn’t give any meaningful data do me. As a bonus: Could there be any reasonable explanation for the application using 100MB of RAM when I read and initialise the data in the application delegate’s -awakeFromNib method and using 50MB after I changed the method name to -applicationDidFinishLaunching:? That seems rather odd to me as well.
Second: Core Data We’re having a database here, which makes it tempting to think about Core Data magic. All the small attempts I did at using Core Data so far failed as soon as I wanted to do anything going beyond Apple’s trivial examples where all data is entered via GUI elements that are hooked up via bindings. Anything else seemed either impossible or a lot of effort. Could it still be that my impression is wrong and that there’s a simple way to import the text file I have to a Core Data database? I figure that might be quite neat and also speed up application startup which currently takes ages (a second or two).


